Introduction
As a digital marketer, having access to data plays a crucial role in my day to day operations. From tasks as simple as budget management, to planning a omni-channel media strategy, I use data to guide decisions that ultimately drive growth for my clients.
With so many different technologies and platforms available, having this data all in one place can be challenging, particularly when there are so many ways that the data can be segmented. This ultimately leads to an inefficient use of time and missed opportunities.
Over the years, I have used various tools to improve data accessibility including several data connectors such as supermetrics and windsor.ai. Although they have their uses, I have always found they have limitations, particularly with large amounts of data and longer lookback windows.
As a result, I decided to build my own data connectors to allow for more flexibility, as well as being able to customise the software to my workflow.
Iteration 1
The first iteration of this data connector used Google Appscripts to request data from the marketing insights endpoint. This was then stored in a Google spreadsheet as a “database”. I used this data in Looker Studio to visualise performance, as well as keep track of monthly budget pacing.
I learnt a huge amount from this project and it taught me a lot of valuable skills. It helped me understand authorisation and authentication, http verbs, pagination, api limits and much more. The project developed over time and continuously improved with re-factored code based on something new i’d learned.
This code served me well for many years until I eventually decided it was time for an upgrade.
Iteration 2
Fast forward a few years and my general understanding of software development had increased significantly. Through my own personal projects and online training courses, I felt in the position to deploy a more robust and scalable solution.
I used node.js for my back-end and Big Query for my database. This was then deployed to Google Cloud Functions. After writing my own functions in iteration 1, it was great to be able to use a package to do most of the heavy lifting. With only a handful of lines of code I was able to request data for all my Facebook accounts, with significant improvements in performance.
The process
If you would like to create your own connector, here are the steps you will need to take. I would recommend you have foundational knowledge in node.js and some experience with Google Cloud console will also be beneficial.
The below steps and code snippets will help you get started with a local connector that you can use to stream data into Big Query.
Step 1 - Getting a Facebook access token
You will need to start by creating a Facebook application using Meta for developers. Once you have configured the app, you can generate an access token which will be used for your API calls. You can read our full guide for creating a Facebook marketing API access token.
Step 2 - Creating a Google Cloud Project
Create a Google Cloud project and set up a billing account. You will need an active project with billing enabled in order to use Big Query API. For more information, you can read Google’s guide for creating a new cloud project.
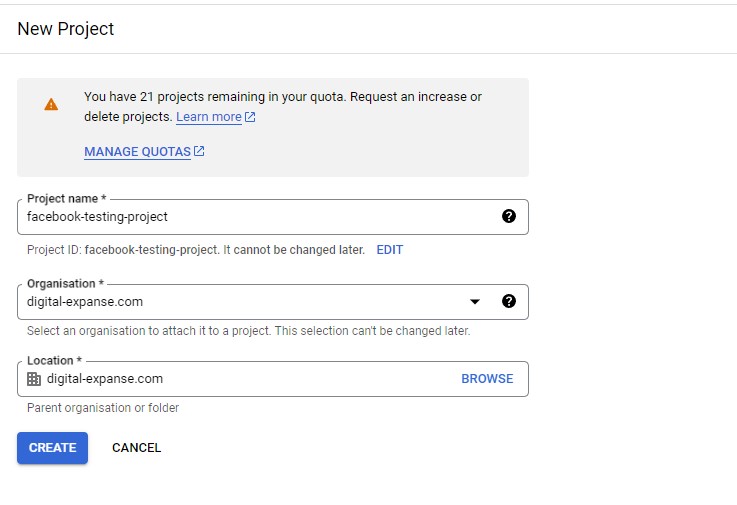
Step 3 - Enabling Big Query
Once you have created your project, you will need to enable the Big Query API. Ensure you are in the correct project and click the menu button -> APIs and services
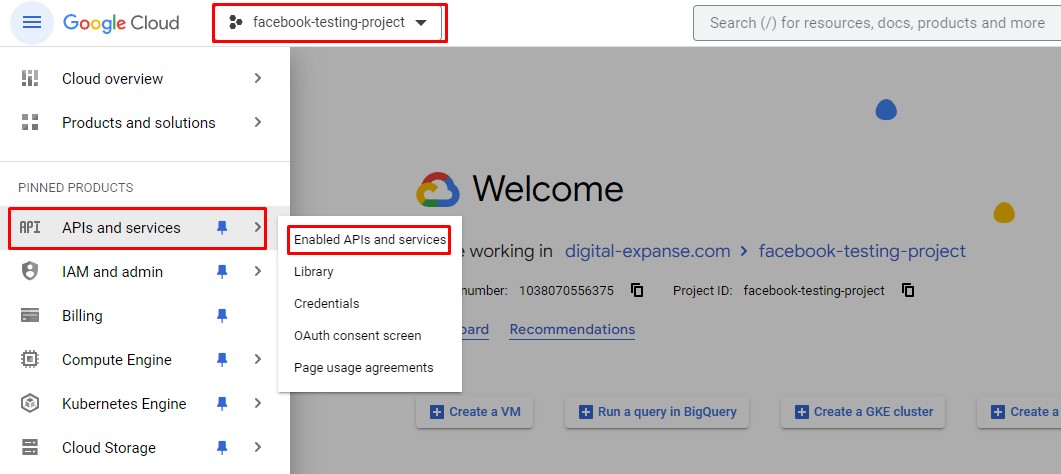
Select the Enable APIs and services button and search for Big Query on the page.
Step 4 - Clone source code
Clone this repository from github. This has all the source code for you to work with.
git clone https://github.com/jasp1994/facebook-data-connector
cd facebook-data-connector
npm install
Step 5 - Configure Google Cloud CLI
Download and configure the Google Cloud CLI. Once you have downloaded the CLI, run this command in your terminal. This will log you into your Google account, giving you access to stream data into the Big Query table.
gcloud auth application-default login
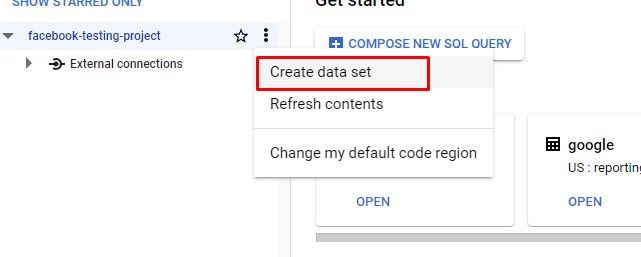
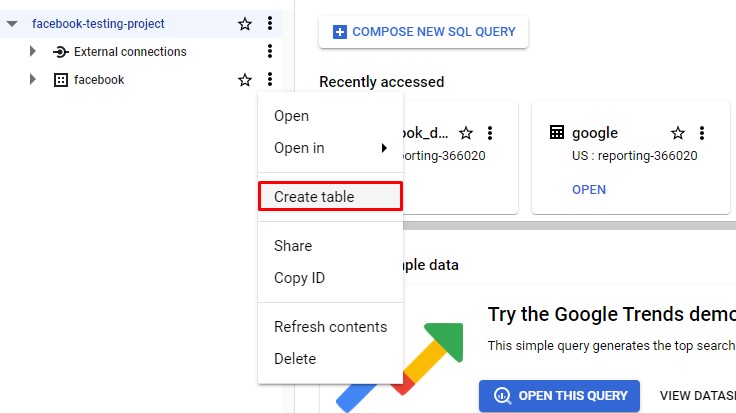
Step 6 - Create a Big Query Dataset & Table
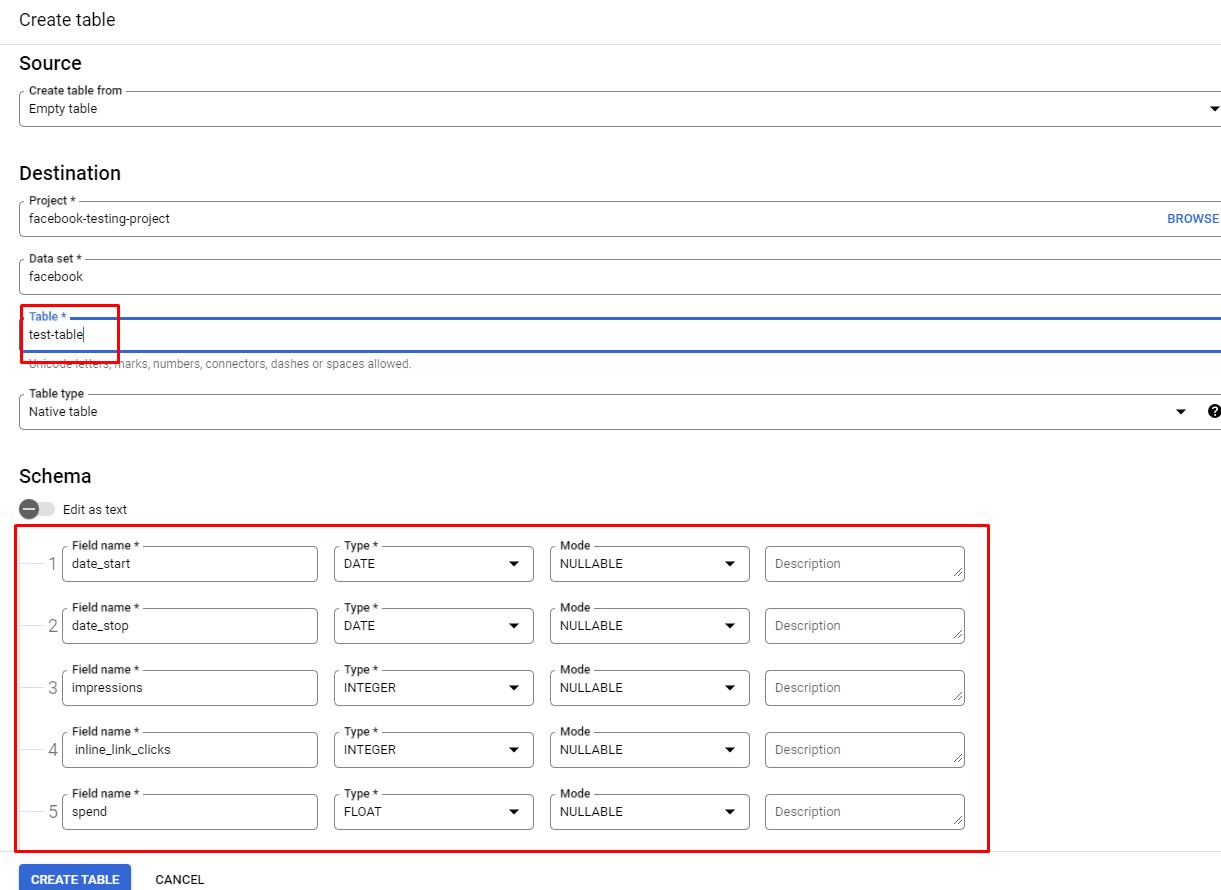
Navigate to Big Query using the side navigation bar and create a new dataset & a new table. For this project the dataset name is “facebook” and the table name is “test-table”.
IMPORTANT
Your table schema field names must exactly match the parameter names from the API.
Step 7 - Update script config
You will need to update your facebook access token and also the account ID you would like to request data for.
If you used a different cloud project name, dataset name or table name, you will also need to update these.
// Configuration
const googleCloudProjectId = "facebook-testing-project"; //Update as needed
const bigquery = new BigQuery({ projectId: googleCloudProjectId });
const datasetId = "facebook"; //Update as needed
const tableId = "test-table"; //Update as needed
//Facebook configuration
const accessToken = "YOUR_ACCESS_TOKEN";
const facebookAccountId = "YOUR_ACCOUNT_ID";
Step 8 - Run it!
If everything runs successfully, your code will execute and you will see the total number of rows inserted into your table.
$ node index
Inserted 24 rows
Step 9 - What’s next?
This guide offers a foundation to build on for your own custom data connector. Using the API documentation, you will be able to expand on this to access more data, with different levels of granularity and over longer time periods. There are many use cases for this data, from